
L’intelligenza artificiale applicata al mondo dei videogiochi potrebbe sembrare un tema di secondo piano, tuttavia ho deciso di parlarne in questo post, perchè il mercato dei videogame è di estremo interesse anche per il business.
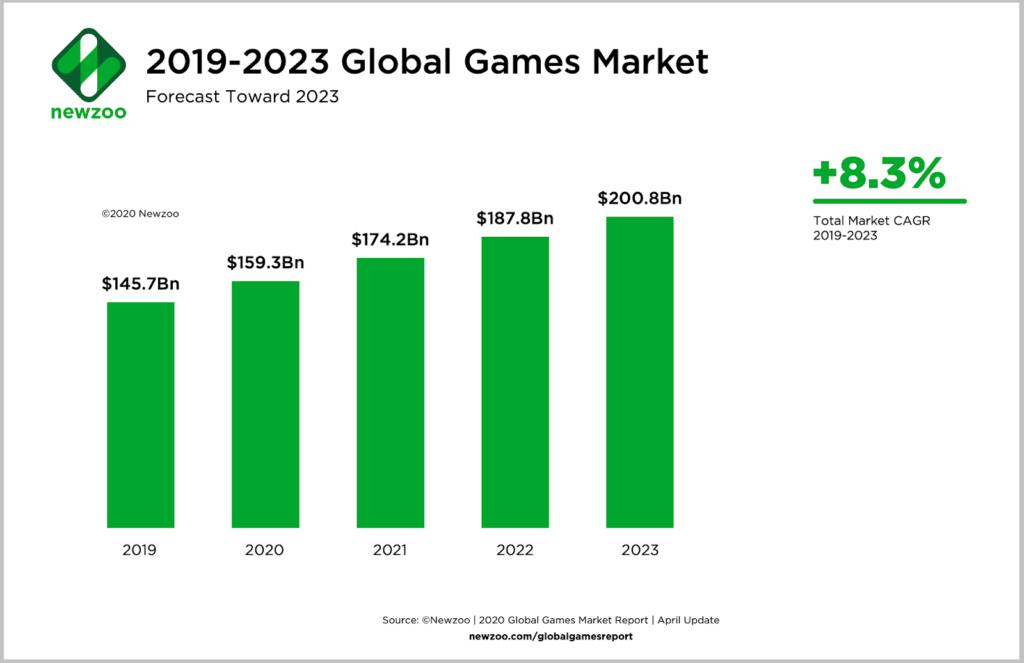
Parliamo di un mercato in continua crescita con un CAGR (Compounded Average Growth Rate) medio annuale previsto di circa l’8,3%
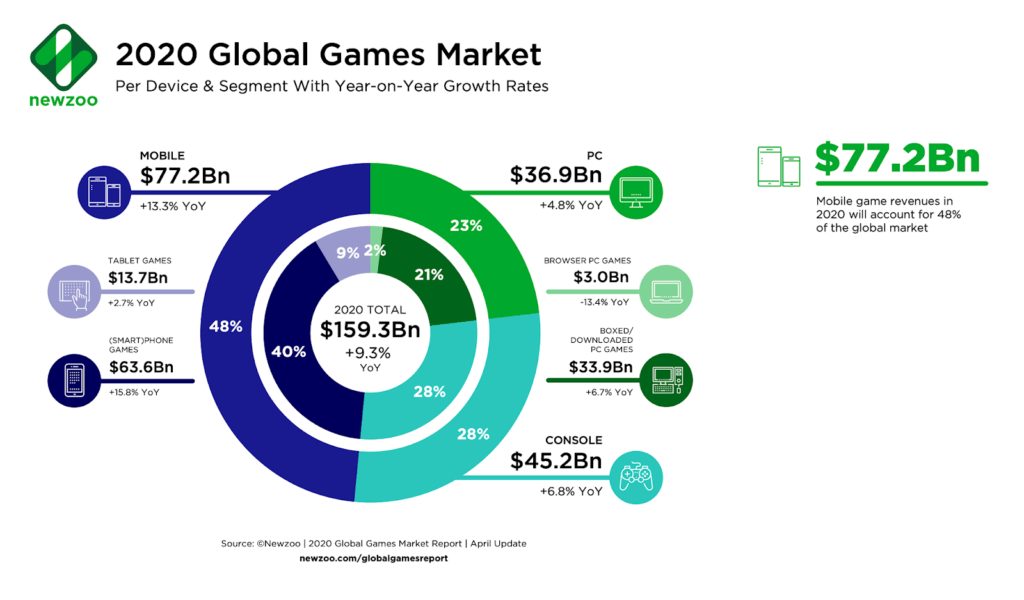
E’ inoltre un mercato pervasivo che prevede l’utilizzo di device di varia natura, dai desktop PC agli smartphone, per arrivare a console ottimizzate per il gaming.
Come possiamo utilizzare il machine learning per applicazioni di gaming?
Gli ambiti di applicazione sono molteplici, ma per sintetizzare qui nel seguito ne citiamo due che ci sembrano di estremo interesse:
- Utilizzare tecniche di machine learning per implementare soluzioni di intelligenza artificiale che emulino giocatori con o contro cui giocare (compagni di squadra o avversari).
- Rendere il gioco più dinamico e interattivo
Ci sono anche alcune insidie nell’adozione di AI per videogiochi: una delle maggiori è probabilmente il rischio di emulare intelligenze troppo “distanti” dal comportamento umano. Il rischio è di annoiare i giocatori oppure – peggio ancora – metterli di fronte ad avversari artificiali troppo perfetti con cui è quasi impossibile vincere.
Ricordiamoci che i videogiochi sono generalmente studiati per stimolare i giocatori presentando livelli di difficoltà ragionevoli e soprattutto graduali.
Venendo alle tecniche di Machine Learning, la tipologia che possiamo considerare quando vogliamo emulare il comportamento per un videogioco è senz’altro quella dell’apprendimento per rinforzo (reinforcement learning).
A differenza dell’apprendimento supervisionato o non supervisionato, il reinforcement learning agisce senza conoscere gli output (non esiste quindi la fase di training tipica degli algoritmi supervised), ma utilizza macchine a stati (per lo più basate su processi di Markov) che associano il passaggio da uno stato all’altro con dei rewards ovvero ricompense.
Consiglio di dare un’occhiata all’articolo di Mauro Comi, data scientist che ha implementato un bell’esempio di gioco chiamato snake, ovvero un simpatico serpente che ha cresce di dimensione man mano che mangia il cibo, ma deve fare attenzione a non “mangiare se stesso”!
Il codice utilizza algoritmi di reinforcement learning per prendere le decisioni, ovvero stabilire la prossima mossa del serpente in funzione del suo stato.
Quello che ho trovato estremamente interessante è che la macchina a stati non è definita semplicemente con una classica matrice tabellare, ma da un algoritmo di “Deep Q-Learning” ovvero una serie di nodi di una rete neurale costruita con Keras:
model = Sequential()
model.add(Dense(output_dim=self.first_layer, activation='relu', input_dim=11))
model.add(Dense(output_dim=self.second_layer, activation='relu'))
model.add(Dense(output_dim=self.third_layer, activation='relu'))
model.add(Dense(output_dim=3, activation='softmax'))
opt = Adam(self.learning_rate)
model.compile(loss='mse', optimizer=opt)Sono tre livelli di deep learning completamente connessi più un livello di output che definisce le azioni del serpente nel videogioco. Vengono poi utilizzate le classiche di funzioni di attivazione non lineari relu e la softmax per l’output.
Maggiori informazioni sul codice sorgente sono disponibili qui.
Provare per credere!

Volete approfondire meglio questi argomenti?
Ecco una lettura interessante su Machine Learning e AI.
