
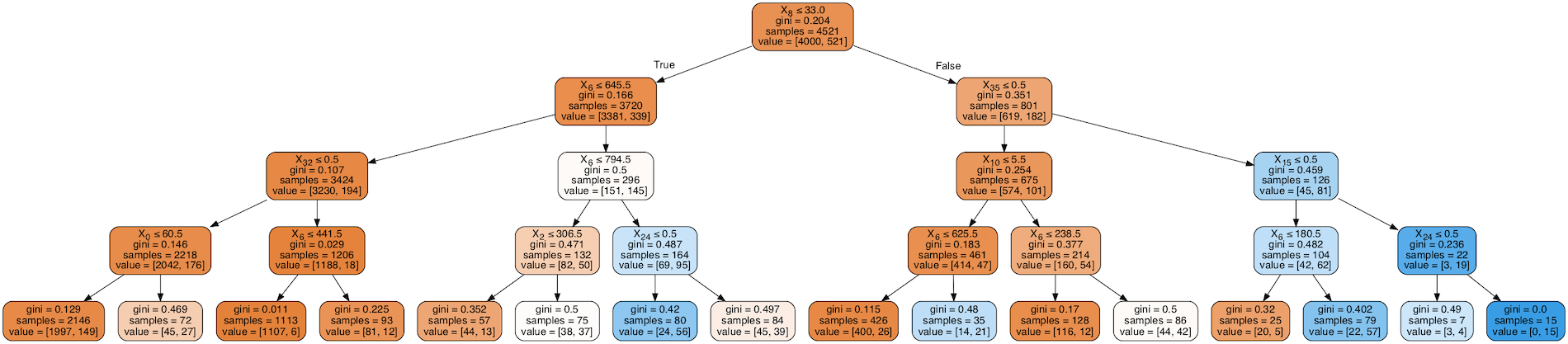
In questo post analizzeremo un problema di classificazione con machine learning, utilizzando alcuni modelli CART (alberi di classificazione e regressione).

Utilizzeremo il seguente dataset di marketing bancario, fornito dal repository UCI Machine Learning:
rif. [Moro et al., 2014] S. Moro, P. Cortez e P. Rita. Un approccio basato sui dati per prevedere il successo del telemarketing bancario. Sistemi di supporto alle decisioni, Elsevier, 62: 22-31, giugno 2014
Si tratta dei risultati di alcune campagne di direct marketing effettuate da una banca portoghese utilizzando telefonate di contact center in outbound, per cercare di vendere ai clienti dei prodotti di deposito pronti contro termine.
I dati etichettati di output che ci interessa predire sono “binari” (colonna y): “yes” nel caso in cui i clienti abbiano accettato l’offerta di deposito bancario o “no” in caso negativo.
Importiamo alcune librerie utili con scikit-learn:
import pandas as pd
from sklearn import ensemble
from sklearn.metrics import mean_absolute_error
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import matplotlib.animation as animation
import numpy as np
from sklearn import preprocessing
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_classification
import seaborn as sns; sns.set()
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
Importiamo quindi il nostro dataset così da averlo a disposizione all’interno di un dataframe che potremo manipolare agevolmente.
df = pd.read_csv(‘http://gosmar.eu/ml/bank.csv’)
print(“Lenght:”, len(df))
print(df.info())
Diamo un’occhiata a questi dati:
Lenght: 4521 <class 'pandas.core.frame.DataFrame'> RangeIndex: 4521 entries, 0 to 4520 Data columns (total 17 columns): age 4521 non-null int64 job 4521 non-null object marital 4521 non-null object education 4521 non-null object default 4521 non-null object balance 4521 non-null int64 housing 4521 non-null object loan 4521 non-null object contact 4521 non-null object day 4521 non-null int64 month 4521 non-null object duration 4521 non-null int64 campaign 4521 non-null int64 pdays 4521 non-null int64 previous 4521 non-null int64 poutcome 4521 non-null object y 4521 non-null object
Abbiamo a disposizione 4521 osservazioni di clienti contattati dal customer care o contact center per proporre il prodotto bancario in questione.
Come vedete conosciamo età, lavoro, stato civile, e N altre informazioni su ogni potenziale cliente.
La feature “campaign“, in particolare, contiene il numero di chiamate che il contact center ha provato ha effettuare verso il potenziale cliente. Se sommiamo i valori di questa colonna otteniamo il numero di chiamate totali effettuate, ovvero 12.630.
Vediamo quanti di questi 4521 clienti hanno acquistato:
len(df[df[“y”] == ‘yes’])
risultato: 521
Ora, supponiamo di essere in grado di predire con una certa accuratezza se un potenziale cliente acquisterà o meno questo prodotto bancario, in base ai dati di training a nostra disposizione… Riuscite a intravedere quante delle 12.630 chiamate (e relativo tempo degli agenti di customer care) avremo risparmiato?
Inoltre, pensate a quanti potenziali clienti avrebbe potuto evitare di contattare (e disturbare) questo call center?
Analizziamo meglio la correlazione delle features:
fig, ax = plt.subplots(figsize=(14,10))
ax = sns.heatmap(df.corr(), cmap=”YlGnBu”, annot = True)
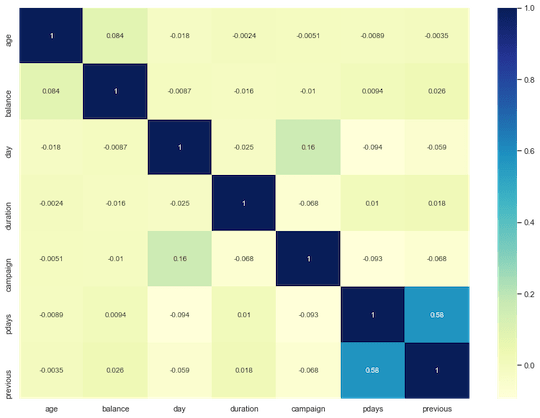
A parte un paio di feature, le altre risultano poco correlate tra loro. Questo depone a favore dell’utilizzo di modelli basati su CART in quanto riduce il rischio di overfitting.
Analizziamo ulteriormente la tipologia dei dati e notiamo come diverse feature siano campi non-numerici. Questa situazione va sanata se desideriamo poter utilizzare la maggior parte degli algoritmi di machine learning disponibili.
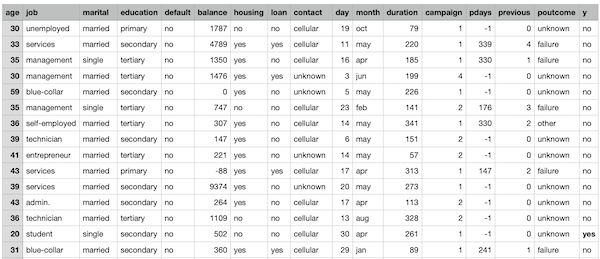
Utilizziamo quindi alcune tecniche di machine learning encoding al fine di trasformare tutto il nostro dataset in valori numerici.
le = LabelEncoder()
le.fit(df[‘default’])
df[‘default’] = le.transform(df[‘default’])
le.fit(df[‘housing’])
df[‘housing’] = le.transform(df[‘housing’])
le.fit(df[‘loan’])
df[‘loan’] = le.transform(df[‘loan’])
le.fit(df[‘y’])
df[‘y’] = le.transform(df[‘y’])
mapper = dict({‘jan’:1,’feb’:2,’mar’:3,’apr’:4,’may’:5,’jun’:6,’jul’:7,’aug’:8,’sep’:9,’oct’:10,’nov’:11,’dec’:12})
df[‘month_new’] = df[‘month’].map(mapper)
df.drop([“month”], axis = 1, inplace = True)
df=pd.get_dummies(df,columns=[‘job’,’marital’,’education’,’contact’,’poutcome’])
print(len(df.columns))
risultato: 38
Ovvero abbiamo trasformato il nostro dataset da 17 feature miste a 38 feature puramente numeriche.
Siamo ora pronti per la fase di training vera e propria.
Separiamo variabili indipendenti dalla feature che vogliamo predire (y):
X=df.drop(‘y’,axis=1)
y=df[‘y’]
Utilizziamo il 70% del nostro dataset per la fase di training e il 30% per quella di test:
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,shuffle=True)
Impostiamo il modello di apprendimento basato su Random Forest e suo adattamento.
model = ensemble.RandomForestClassifier(n_estimators=200, criterion=’gini’, max_depth=None,
min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0,
max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None,
random_state=None, verbose=0, warm_start=False,
class_weight={0:1,1:2})
model.fit(X_train,y_train)
Notiamo che abbiamo utilizzato 200 stimatori (200 alberature random) e abbiamo adottato una tecnica di sampling stratificato per dare più importanza o peso alla classe y=1 (che è obiettivamente molto meno presente, ma importante).
Questo dovrebbe migliorare le performance del nostro modello, riducendo anche il Bias associato.
Valutiamo l’accuratezza del nostro modello e la matrice di confusione:
print(“Accuracy on training set is : {}”.format(model.score(X_train, y_train)))
print(“Accuracy on test set is : {}”.format(model.score(X_test, y_test)))
y_test_pred = model.predict(X_test)
print(classification_report(y_test, y_test_pred))
Accuracy on training set is : 1.0
Accuracy on test set is : 0.9086219602063376
precision recall f1-score support
0 0.92 0.99 0.95 1214
1 0.70 0.23 0.35 143
accuracy 0.91 1357
macro avg 0.81 0.61 0.65 1357
weighted avg 0.89 0.91 0.89 1357
#Print the confusion matrix
from sklearn import metrics
print(metrics.confusion_matrix(y_test, y_test_pred))
[[1200 14] [ 110 33]]
Notiamo come l’accuratezza pari a 0.91 è ricavabile anche dal rapporto tra la somma dei valori in diagonale e quelli totali della matrice di confusione.
Ebbene, abbiamo ottenuto un’accuratezza del 91%… Non male per un classificatore basato su CART!
Possiamo anche concludere che – se la banca portoghese in questione avesse utilizzato queste tecniche di machine learning prima di effettuare la sua campagna di marketing – avrebbe probabilmente potuto effettuare circa 1500 telefonate* (al posto delle oltre 12.000) con un margine di errore del 9% sulla chiusura della trattativa!
*Il ragionamento tiene conto già del fatto che i 521 clienti che hanno accettato l’offerta fossero stati chiamati in media circa 3 volte cadauno.
Vuoi approfondire questi argomenti?
Ecco una lettura interessante su Machine Learning e AI.
