

Come descritto sul sito ufficiale di OpenAI, Whisper è un sistema di riconoscimento vocale automatico (ASR: Automatic Speech Recognition) addestrato su 680.000 ore di dati supervisionati multilingue e multitasking raccolti da tutto il web.
L’utilizzo di un set di dati così ampio e diversificato porta a una maggiore robustezza nel riconoscimento vocale anche in presenza di accenti particolari, rumore di fondo accentuato e linguaggio specifico o tecnico. Inoltre, consente la trascrizione in più lingue, nonché la loro traduzione in inglese.
L’obiettivo di OpenAI con Whisper è mettere a disposizione modelli open source e codice di inferenza (predizione) che rappresentino una base per la creazione di applicazioni di mercato utili oltre al supporto per ulteriori ricerche sull’elaborazione vocale e soluzioni di trascrizione.
I modelli di machine learning adottati per Whisper sono basati sul concetto di Transformer che adotta un sistema ormai consolidato di encoder-decoder (ho già accennato ai Transformer in un capitolo dedicato all’interno del mio libro su Machine Learning).
Vediamolo subito in azione con alcune righe di codice Python che ci consentono di utilizzare i modelli in questione per effettuare una conversione da voce a testo.
Importiamo la libreria per utilizzare whisper e carichiamo uno dei modelli per convertire una conversazione di esempio tra cliente e operatore di customer care:
#import library
import whisper
#Let’s use one of the Whisper models:
model = whisper.load_model(“base“)
result = model.transcribe(‘/path/conversation.wav’)
print(result[“text”])
In questo caso ecco un estratto della conversazione che Whisper è stato in grado di convertire in testo:
Hello, and thank you for calling the bank. This is Ashley speaking. How may I help you today? Hi I just need to cancel my card. I was a debit card and a credit card. It's my card was broken into so I need a cancel everything. Okay, and who am I speaking with? Oh, and this is Melissa Bivens B-I-D-E-N-S B-I-D as in dog No, Z is in Perfect. Any words? Voice Okay, B-I-Z-V-E and then can you spell that last card again for me? I'm on the start over a B as in a boy. I-Z-Z-V-E as in everything and and Perfect and your first name one more time just since we sent so much time on that last name Melissa, perfect. Thank you so much...
Il metodo model.transcribe di cui sopra ha caricato la versione di modello denominata “base”, ma Whisper mette a disposizione N modelli, che sono stati addestrati con un numero di parametri sempre più elevato. Eccone una lista:
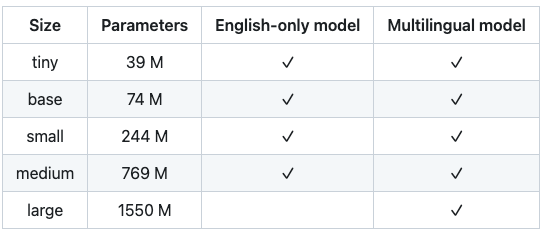
Da notare come, a Dicembre 2022, sia stato rilasciato un ulteriore modello denominato large-v2 addestrato con 2,5 Epoch superiori rispetto al large V1 in tabella.
I grafici seguenti mostrano l’andamento delle performance dei modello large-v2, per quello che riguarda WER* e Accuratezza.
* WER è acronimo di Word Error Rate ed è un parametro fondamentale per valutare la bontà di un sistema di riconoscimento vocale (ovviamente minore è il WER, maggiore è la bontà della soluzione).
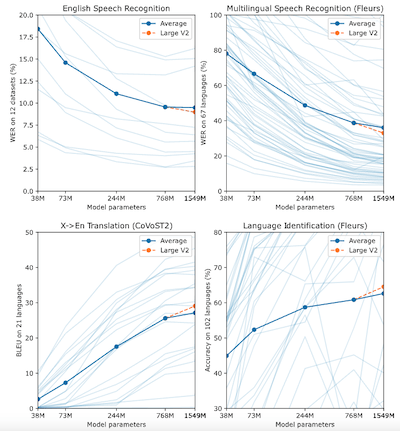
Rispetto ai modelli sopra elencati è utile considerare che tiny e base sono modelli più semplici (si fa per dire) ovvero addestrati su un numero inferiore di parametri: essi avranno un WER più elevato, ma saranno in grado di convertire una conversazione vocale in testo molto rapidamente. I modelli superiori (small, medium, large) saranno via via più accurati e presenteranno WER inferiore, a discapito però della rapidità di trascrizione.
A parità di potenza di calcolo quindi, man mano che utilizzeremo modelli Whisper superiori, otterremo delle conversioni da voce a testo con qualità superiore, impiegando però maggiore tempo di elaborazione.
E’ evidente, quindi, che occorra scegliere il modello in funzione delle necessità: ad esempio, se desidero semplicemente convertire una conversazione vocale in testo senza nessuna esigenza di effettuare questa elaborazione rapidamente (ad esempio voglio effettuare una trascrizione per fare successivamente delle analisi) allora potrò adottare modelli anche medium o large.
Al contrario, se dovessi convertire un parlato in tempo reale, per visualizzarne immediatamente il testo e non avessi a disposizione potenze di calcolo estreme, allora mi converrebbe scegliere un modello whisper tiny o base.
Possiamo provare anche ad effettuare la trascrizione partendo da un video youtube. Nell’esempio seguente prendiamo uno dei video pubblici di uno spezzone tratto dal film il Gladiatore.
Estraiamone prima solo la parte audio:
#Importing Pytube library
import pytube
#Reading the above Gladiator movie Youtube link
video = ‘https://www.youtube.com/watch?v=hE9Lmsmzhnw’
data = pytube.YouTube(video)
#Converting and downloading as MP4 file
audio = data.streams.get_audio_only()
audio_downloaded = audio.download()
Applichiamo il modello “small” e visualizziamo il risultato:
model = whisper.load_model(“small”)
text = model.transcribe(audio_downloaded)
#printing the transcribe
text[‘text’]
" MUSIC CHEERING Guys! Guys! MUSIC Your fame is well-deserved, Spaniards. I don't think there's ever been a gladiator to match you. Just for this young man, he insists you are Hector Reborn. What was the turkish? Why doesn't the hero reveal himself and tell us all your real name? You do have a name. My name is Gladiator. How dare you show your back to me? Slave! Will you remove your helmet and tell me your name? My name is Maximus Decimus Meridius. Commander of the armies of the North, general of the Felix legions. Loyal servant to the true emperor, Marcus Aurelius. Father to a murdered son, husband to a murdered wife. And I will have my vengeance in this life or the next. Ham! CHEERING CHEERING CHEERING Arm! Brace! CHEERING MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC MUSIC"
Non male il risultato!
Per chi fosse interessato a comprendere meglio cosa c’è dietro, questa è l’architettura Transformer basata su encoder-decoder di Whisper:
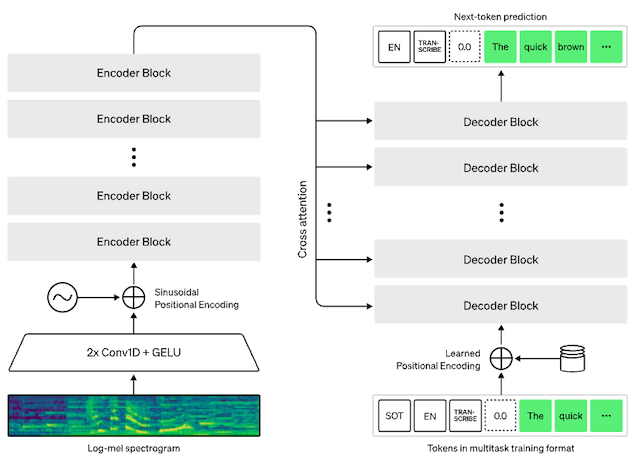
L’audio in ingresso viene suddiviso in blocchi di 30 secondi, convertito in uno spettrogramma log-Mel e quindi passato a un codificatore. Un decodificatore viene addestrato per prevedere la didascalia di testo corrispondente, mescolata con token speciali che utilizzano il singolo modello per eseguire attività secondo le necessità, come l’identificazione della lingua, i timestamp a livello di frase, la trascrizione vocale multilingue o la traduzione vocale in inglese.
Per inciso, abbiamo già approfondito l’utilizzo di algoritmi basati su MEL in questo precedente articolo, dove parlavamo di MFCC (Mel Frequency Cepstral Coefficient) in combinazione a Reti Neurali per il riconoscimento vocale.
Questa volta OpenAI con Whisper ha adottato una metodologia simile, ma con tecniche più avanzate di Machine Learning passando dal puro utilizzo di reti neurali a quello dei Transformers (attention is all you need)!
Tornando alla trascrizione della conversazione iniziale, il codice seguente ci consente di decodificare il primo blocco di 30 secondi della conversazione e di rilevarne anche la lingua.
model = whisper.load_model(“base”)
#load the audio and adapt it to fit 30 seconds
audio = whisper.load_audio(‘/Users/diego.gosmar/Diego/AI/Whisper/conversation1.wav’)
audio = whisper.pad_or_trim(audio)
#make log-Mel spectrogram
mel = whisper.log_mel_spectrogram(audio).to(model.device)
#detect the language and print it
_, probs = model.detect_language(mel)
print(f”Detected language: {max(probs, key=probs.get)}”)
#decode the initial 30 seconds of audio
options = whisper.DecodingOptions(fp16 = False)
result = whisper.decode(model, mel, options)
#print the results
print(result.text)
Detected language: en Hello and thank you for calling the bank. This is Ashley speaking. How may I help you today? Hi, I just need to cancel my card. I have a debit card and a credit card. It's my card...
Inizialmente sono stati usati Python 3.9.9 e il framework di Machine Learning PyTorch 1.10.1 per addestrare e testare i modelli, ma la base di codice dovrebbe essere compatibile anche con altre versioni di Python e le più recenti versioni di PyTorch. Una parte del codice dipende anche da alcuni librerie Python specifiche, in particolare tiktoken di OpenAI per la loro rapida implementazione di tokenizzazione (by the way, abbiamo già trattato anche i temi di embedding e tokenizzazione in un precedente articolo dedicato all’untilizzo di reti neurali per il sentiment analysis).
Volete approfondire meglio questi argomenti?
Ecco una lettura interessante su Machine Learning e AI.
