Come descritto sul sito ufficiale di OpenAI, Whisper è un sistema di riconoscimento vocale automatico (ASR: Automatic Speech Recognition) addestrato su 680.000 ore di dati supervisionati multilingue e multitasking raccolti da tutto il web.
L’utilizzo di un set di dati così ampio e diversificato porta a una maggiore robustezza nel riconoscimento vocale anche in presenza di accenti particolari, rumore di fondo accentuato e linguaggio specifico o tecnico. Inoltre, consente la trascrizione in più lingue, nonché la loro traduzione in inglese.
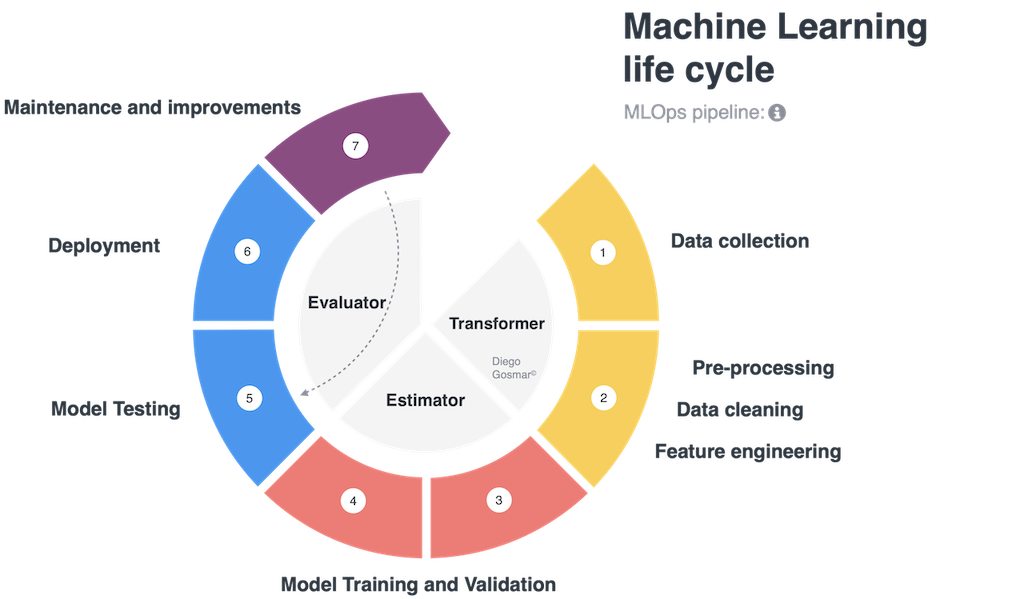
Con il crescente utilizzo delle tecniche di Machine Learning (ML) in varie industry, stiamo assistendo ad un aumento del numero di progetti e della loro complessità. Questo genera da un lato l’esigenza di maggiore governance ovvero capacità di orchestrare e controllare la catena di sviluppo e rilascio sull’intera ciclo di vita del ML (preprocessing, model training, testing, deployment) e dall’altro lato l’esigenza di scalabilità, ovvero riuscire a replicare in maniera efficiente parti intere del processo per gestire molteplici modelli di ML (Machine Learning).
Una recente ricerca in USA, effettuata per comprendere le tendenze relative al mondo del Machine Learning per il 2021, ha elaborato un sondaggio effettuato su un campione significativo di 400 aziende di varia dimensione: il 50% di queste sta gestendo attualmente più di 25 modelli di ML e il 40% del totale gestisce oltre 50 modelli di ML. Tra le organizzazioni di grande dimensione (oltre 25.000 collaboratori) il 41% di esse possiede oltre 100 algoritmi di ML in produzione!
Abbiamo visto in uno dei post precedenti come utilizzare delle reti neurali convoluzionali per effettuare il riconoscimento vocale di semplici numeri da zero a nove.
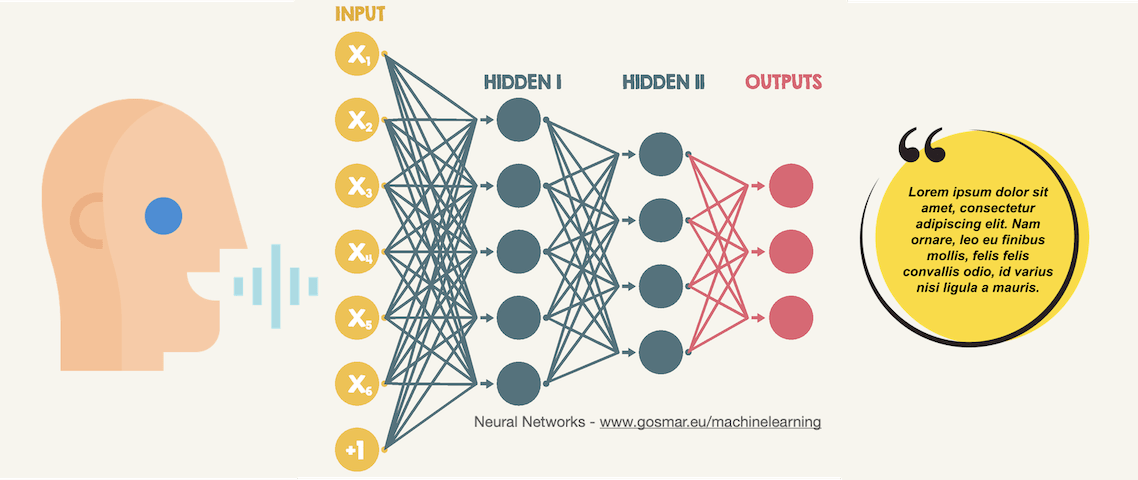
Nella pratica il riconoscimento vocale presenta performance superiori adottando delle particolari reti neurali denominate Recurrent Neural Network, ovvero “Reti Neurali Ricorrenti” (RNN per semplicità).
A differenza delle reti neurali feed-forward “semplici”, le RNN elaborano come input sia i dati effettivamente forniti come tali, sia alcuni dei dati di output in maniera retroattiva. Questo consente loro di lavorare “conmemoria“.
L’intelligenza artificiale applicata al mondo dei videogiochi potrebbe sembrare un tema di secondo piano, tuttavia ho deciso di parlarne in questo post, perchè il mercato dei videogame è di estremo interesse anche per il business.
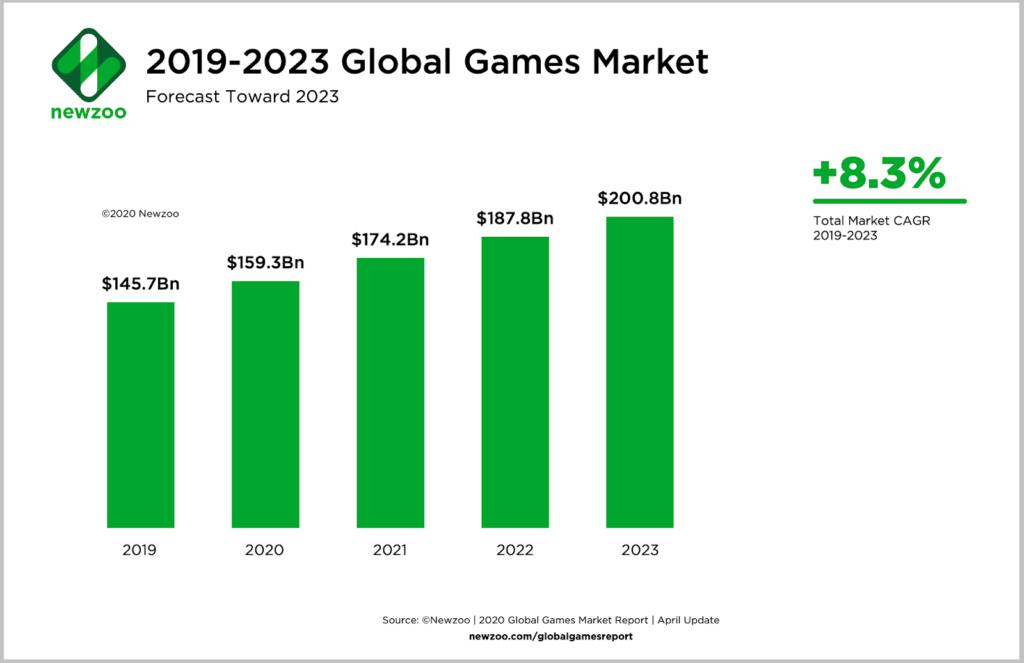
Parliamo di un mercato in continua crescita con un CAGR (Compounded Average Growth Rate) medio annuale previsto di circa l’8,3%
Gaming CAGR
E’ inoltre un mercato pervasivo che prevede l’utilizzo di device di varia natura, dai desktop PC agli smartphone, per arrivare a console ottimizzate per il gaming.
Oggi vediamo un esempio di CNN (reti neurali convoluzionali) applicato al riconoscimento vocale (speech recognition). Obiettivo del nostro modello di machine learning basato su algoritmi CNN di Deep Learning sarà quello di riuscire a classificare alcune parole semplici, iniziando dai numeri da zero a nove.
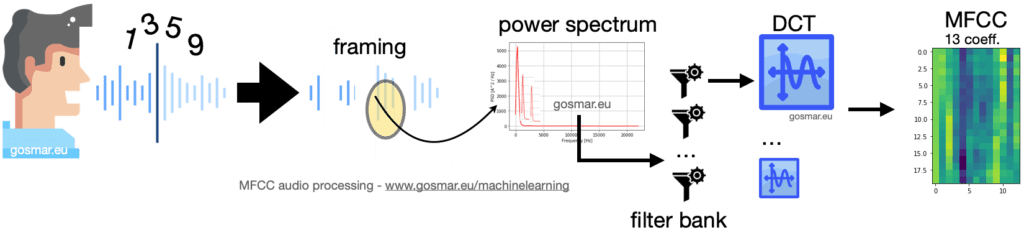
Per estrarre delle caratteristiche distintive del parlato adotteremo prima una procedura di codifica della voce piuttosto utilizzata in ambito ASR (Automatic Speech Recognition) denominata Mel Frequency Cepstral Coefficient o più semplicemente MFCC.
Grazie alla tecnica MFCC saremo in grado di codificare ogni singola parola pronunciata vocalmente in una sequenza di vettori ognuno dei quali lungo 13: i coefficienti ottenuti con l’algoritmo MFCC.
Nel nostro caso – essendo le singole parole rappresentate da numeri di una sola cifra – andremo per semplicità a codificare ogni singolo numero con una matrice 48 x 13.
L’immagine precedente mostra la catena dei principali moduli coinvolti in un processo di codifica MFCC: il segnale vocale viene segmentato in più frame di durata adeguata nel dominio del tempo (generalmente 25-40 ms). Per ognuno di questi segmenti andiamo a calcolare la trasformata in frequenza e quindi lo spettro di potenza. Il risultato è fornito in input a una serie di filtri parzialmente sovrapposti (filter bank) che calcolano la densità spettrale di energia corrispondenti a differenti intervalli di frequenza del nostro spettro di potenza.
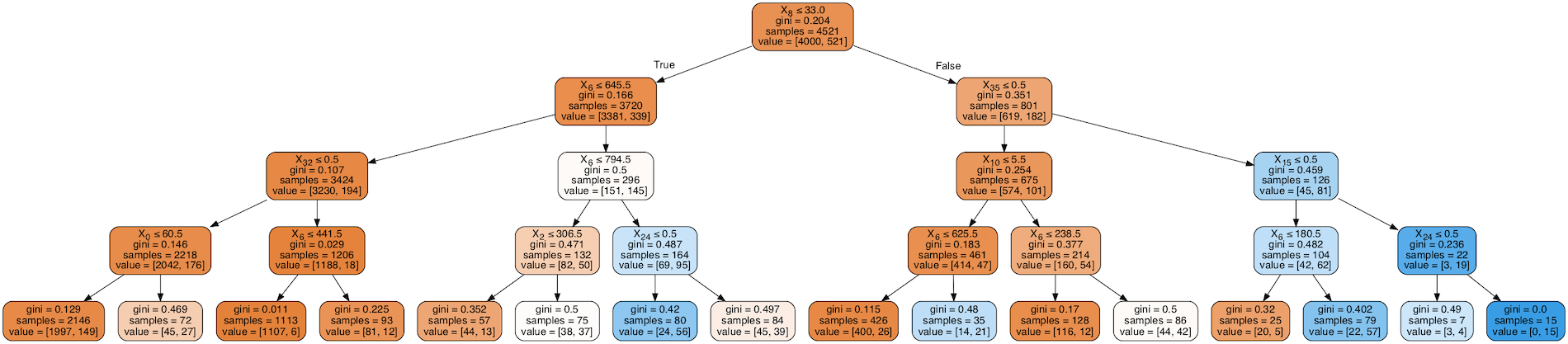
In questo post analizzeremo un problema di classificazione con machine learning, utilizzando alcuni modelli CART (alberi di classificazione e regressione).
Utilizzeremo il seguente dataset di marketing bancario, fornito dal repository UCI Machine Learning: rif. [Moro et al., 2014] S. Moro, P. Cortez e P. Rita. Un approccio basato sui dati per prevedere il successo del telemarketing bancario. Sistemi di supporto alle decisioni, Elsevier, 62: 22-31, giugno 2014
Si tratta dei risultati di alcune campagne di direct marketing effettuate da una banca portoghese utilizzando telefonate di contact center in outbound, per cercare di vendere ai clienti dei prodotti di deposito pronti contro termine. I dati etichettati di output che ci interessa predire sono “binari” (colonna y): “yes” nel caso in cui i clienti abbiano accettato l’offerta di deposito bancario o “no” in caso negativo.
Importiamo alcune librerie utili con scikit-learn:
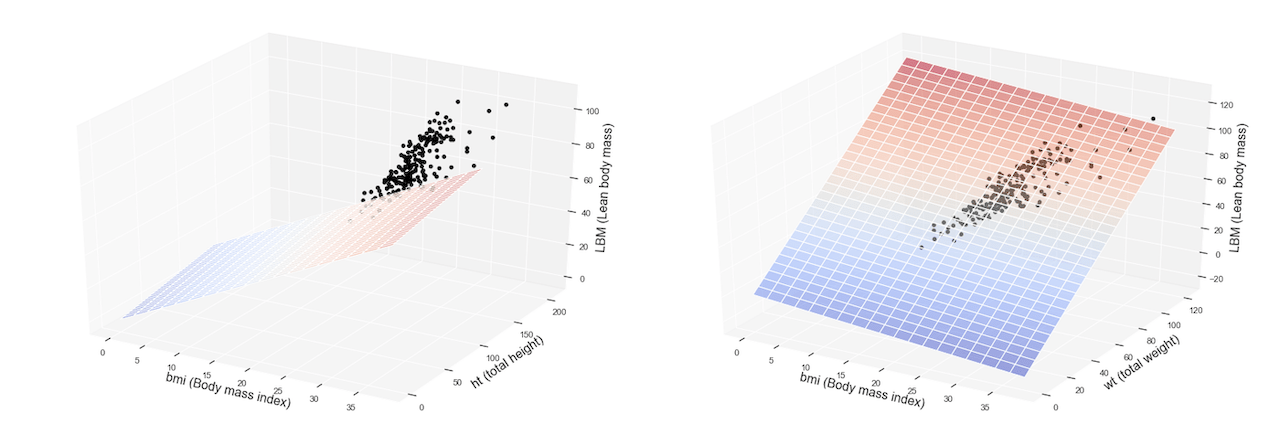
Abbiamo già visto in questo post precedente un esempio di regressione lineare semplice, ovvero un set di algoritmi e tecniche per machine learning in grado di predire una variabile di output data una sola variabile indipendente, quindi tramite una funzione lineare Y = c1 + c2X.
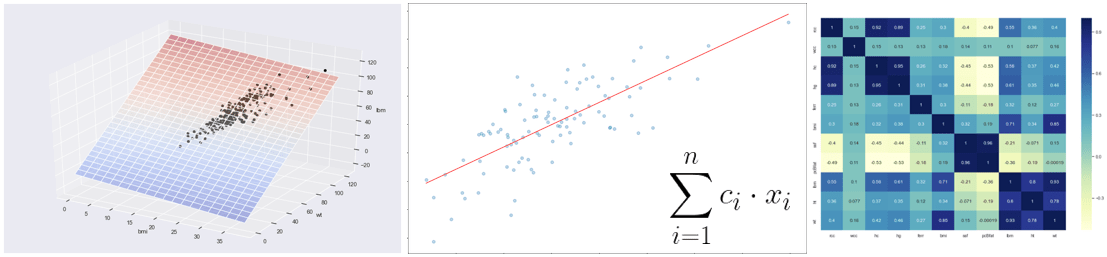
Oggi vediamo invece la sua estensione, ovvero come predire Y in funzione di più variabili indipendenti lineari (X1, X2, X3 etc… etc…). Questa tipologia di modelli prende anche il nome di regressione lineare multipla.
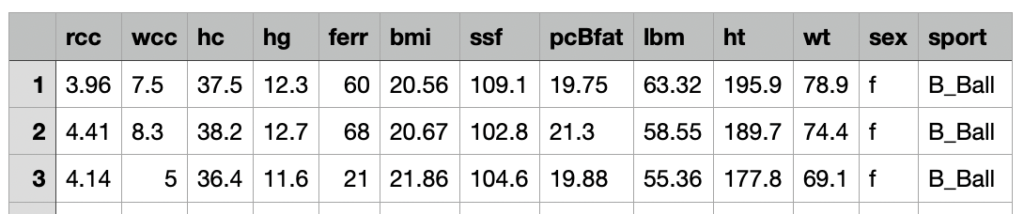
Riutilizziamo il dataset relativo alle analisi del sangue effettuate alcuni anni fa su atleti professionisti australiani in varie discipline sportive: riferimento Telford, R.D. e Cunningham, R.B. 1991 – sesso, sport e dipendenza dell’ematologia dalle dimensioni corporee in atleti altamente allenati. Medicina e scienza nello sport 23: 788-794.
Il dataset in questione contiene 13 feature relative a 202 osservazioni.
In questo primo articolo giocheremo con la regressione lineare con l’obiettivo di prendere confidenza su alcuni concetti chiave relativi al machine learning.
Le reti neurali convoluzionali, le reti neurali ricorrenti, gli algoritmi di SVN, e di regressione logistica sono ottime tecniche per realizzare predizioni su dati estremamente complessi, compresi quelli che possiedono caratteristiche non lineari.
Tuttavia, la regressione lineare è un ottima soluzione per effettuare delle predizioni su dati che presentano correlazioni lineari.
Sport Blood Test dataset
Consideriamo un set di dati relativo ad alcuni atleti australiani raccolti in uno studio di qualche tempo fa, per verificare come le varie caratteristiche del sangue cambiavano al variare dellla corporatura sportiva dell’atleta. Questi dati sono stati la base per le analisi riportate da Telford e Cunningham nel 1991.
Chiunque sia interessato a conoscere meglio lo studio in esame può fare riferimento a Telford, R.D. e Cunningham, R.B. 1991: sesso, sport e dipendenza dell’ematologia dalle dimensioni corporee in atleti altamente allenati. Medicina e scienza nello sport 23: 788-794: https://europepmc.org/article/med/1921671
Utilizzeremo il linguaggio Python con l’ambiente Jupyter Notebook per realizzare questo modello di machine learning.