
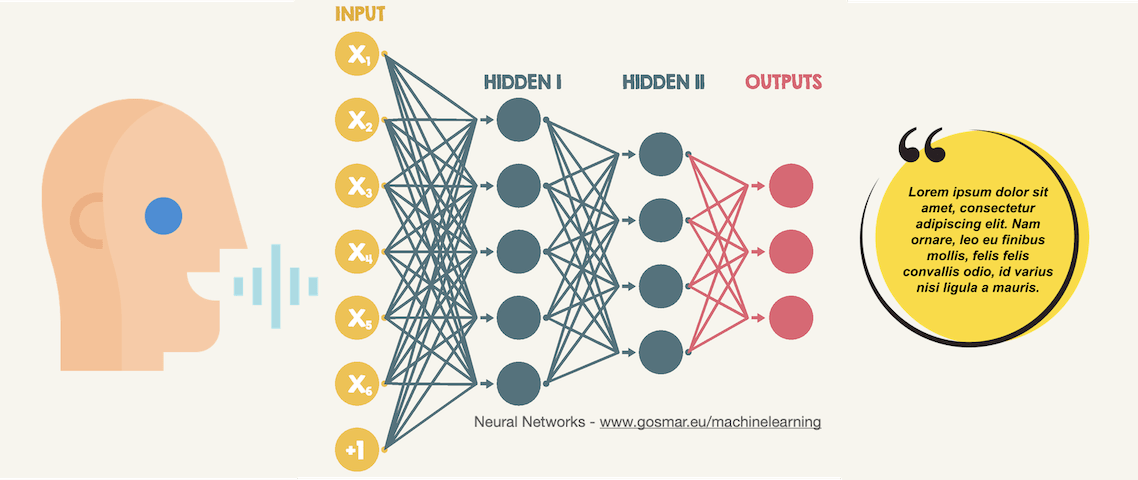
Deep-learning ASR convolutional-neural-networks
Oggi vediamo un esempio di CNN (reti neurali convoluzionali) applicato al riconoscimento vocale (speech recognition).
Obiettivo del nostro modello di machine learning basato su algoritmi CNN di Deep Learning sarà quello di riuscire a classificare alcune parole semplici, iniziando dai numeri da zero a nove.
Per estrarre delle caratteristiche distintive del parlato adotteremo prima una procedura di codifica della voce piuttosto utilizzata in ambito ASR (Automatic Speech Recognition) denominata Mel Frequency Cepstral Coefficient o più semplicemente MFCC.
Grazie alla tecnica MFCC saremo in grado di codificare ogni singola parola pronunciata vocalmente in una sequenza di vettori ognuno dei quali lungo 13: i coefficienti ottenuti con l’algoritmo MFCC.
Nel nostro caso – essendo le singole parole rappresentate da numeri di una sola cifra – andremo per semplicità a codificare ogni singolo numero con una matrice 48 x 13.
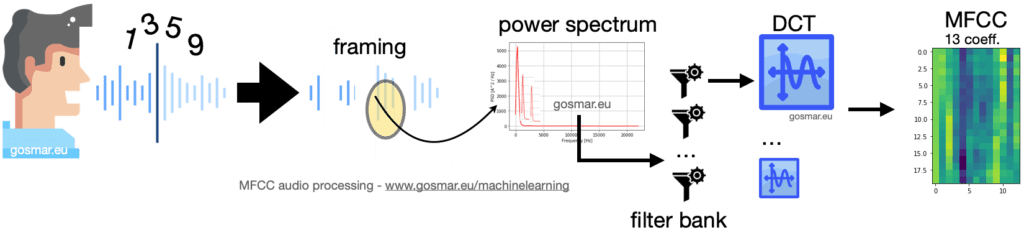
L’immagine precedente mostra la catena dei principali moduli coinvolti in un processo di codifica MFCC: il segnale vocale viene segmentato in più frame di durata adeguata nel dominio del tempo (generalmente 25-40 ms).
Per ognuno di questi segmenti andiamo a calcolare la trasformata in frequenza e quindi lo spettro di potenza.
Il risultato è fornito in input a una serie di filtri parzialmente sovrapposti (filter bank) che calcolano la densità spettrale di energia corrispondenti a differenti intervalli di frequenza del nostro spettro di potenza.