
Deep-learning ASR convolutional-neural-networks
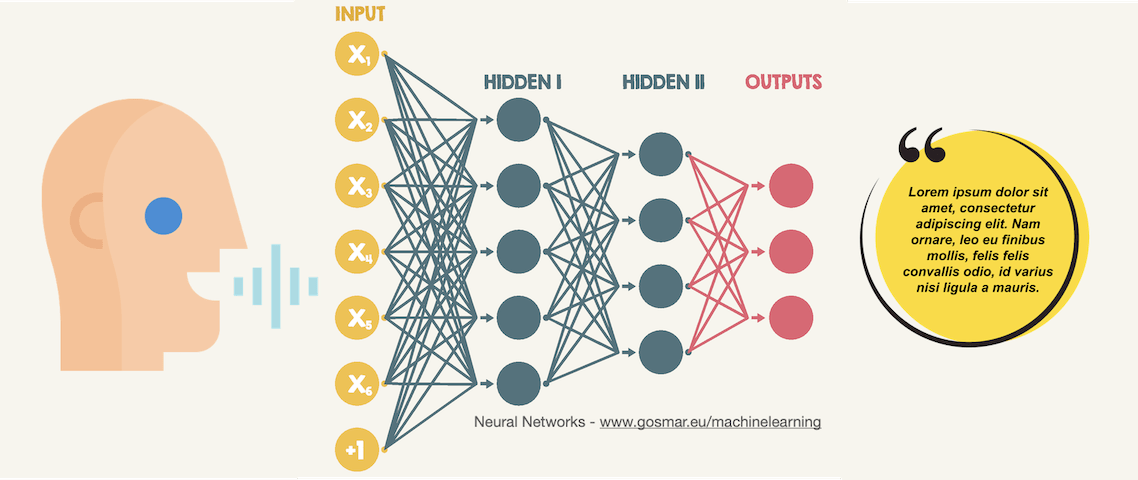
In this post we are going to see an example of CNN (convolutional neural networks) applied to speech recognition application.
The goal of our machine learning model based on CNN’s Deep Learning algorithms will be to classify some simple words, starting with numbers from zero to nine.
To extract the distinctive features of speech, we will first adopt a voice coding procedure rather used in the ASR area (Automatic Speech Recognition) named Mel Frequency Cepstral Coefficient or more simply MFCC.
Thanks to the MFCC technique we will be able to encode every single word spoken vocally into a sequence of vectors, each of them 13 value-long representing the MFCC algorithm coefficients.
In our case – being the single words represented by single-digit numbers – we will go to encode each single number by using a 48 x 13 matrix.
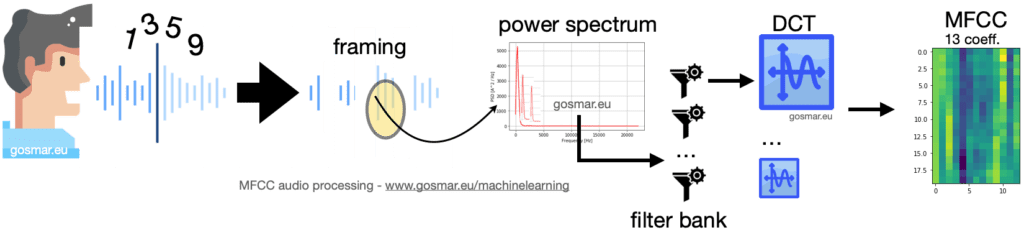
The previous image shows the chain of the main modules involved during an MFCC encoding process: the voice signal is segmented into several frames of proper duration in the time domain (generally 25-40 ms).
Continue reading “Neural networks and speech recognition”